

You may be familiar with the Kent Beck quote, “Make it work. Make it right. Make it fast.” This is a great fundamental approach to programming. When we iterate on our initial implementation or design, we get a higher quality result.
While we tend to associate higher quality with higher costs, that correlation breaks down when evaluating code. Investing in higher quality code drives costs down in the short and long term while simultaneously creating new value for both your business and your consumers.
At Vervint, we know that iterative coding leads to better code and coding practices. To illustrate why, we’ll explore three levels of development for implementing a new endpoint with search capability backed by a lambda function and an external search engine. With this narrow focus, we can explore exactly how the quality of this development approach can positively impact costs — even when delivering the same (or better) outcome.
Code Iterations for Cost Optimization
There’s no real limit on how many iterations you can pursue to optimize your code, but your greatest return on investment (ROI) is going to come from following the following three approaches:
Make Your Code Work
The primary concern of making your code work is functionality. You want to get a result, regardless of whether it’s well documented or efficient. This is part one of our iterative approach to a problem.
Make Your Code Right
With mission-critical functionality in place, you may recognize that your code could be more efficient and create less tech debt with some obvious updates.
Make Your Code Fast (Better)
Usually, writing software happens at a fast pace. Growing a solution means figuring out which implementations scale, and which implementations need to be sunset. As a codebase becomes more complex, refactoring takes place and efficiency becomes front of mind. Within an Agile or SAFe framework, we may even see an Epic or Story to reduce AWS Lambda invokes or investigate database spikes, but those typically happen down the line in a project’s development cycle. When you consider making code fast, you’re asking, “How can we get ahead of inefficiencies?”
The Project: Create Author Search Functionality
Many brands host user-focused content such as posts, articles, memes, recipes, products, etc. This allows them to grow their user community, add value for consumers, increase brand loyalty, attract new customers, build affiliate, or brand ambassador partnerships, enhance user experiences and further other business goals.
To help users find their favorite authors in a particular content management system (CMS), we’ll be building some basic search functionality using the three approaches outlined above. Each approach will have the same outcome: returning a list of authors based on a user’s search. And each approach will use the same architectural elements:
- A new endpoint (for web or mobile using API Gateway) to search an external CMS
- A service (AWS Lambda) to manage new endpoint requests
- A search engine’s (Algolia/Elastic Search/Other) API
Make Your Code Work: AWS Console
To “make it work,” we simply want to get a result that makes sense. The method might be messy and borderline incomprehensible, but it will accomplish the goal. To create a new web or mobile endpoint and lambda via AWS Console (along with a trigger to a new API Gateway endpoint), the primary steps include:
- Creating a lambda function
- Creating an endpoint in API Gateway
- Test!
So, let’s get started!
Create a Lambda Function
As we get started creating our services, we want to keep in mind the high-level architecture:
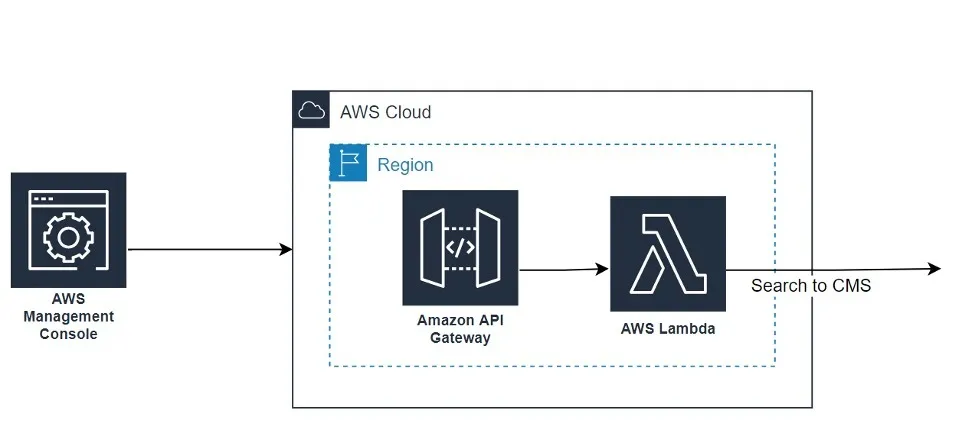
To “make it work,” our initial deployment will be exclusively done via the AWS Management Console, so the first thing to do is create a lambda.
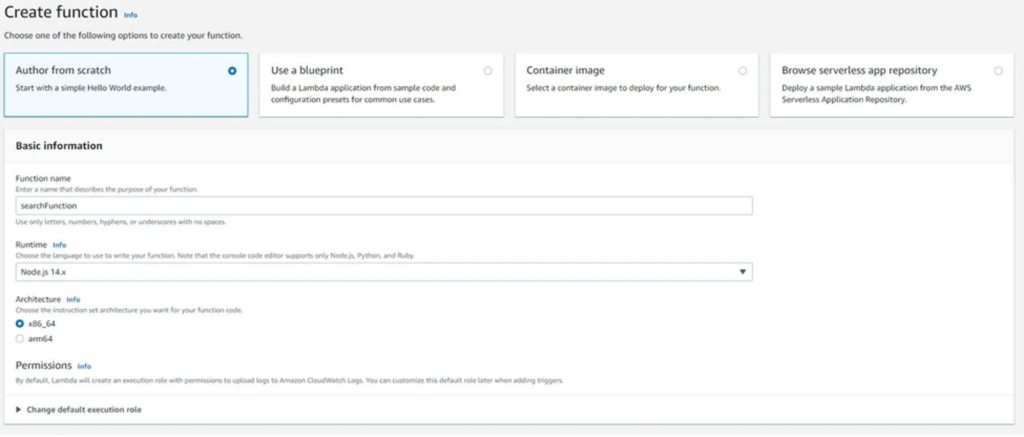
There are plenty of configurable fields here. Note that you can also choose from several languages. Vervint usually works in Node.js for our lambdas, so my example will as well.
Once you click “Create,” you can add code to index.js in the AWS Lambda in the console. You’ll be able to find that area under your AWS Lambda main page in the “Code Source” section.
In the index.js area, you will want to start adding calls to your external APIs and formatting the data returned (if needed). One call will be to search for the data using the search engine of your choosing. All the returned data will bubble back up to the endpoint and will be consumable for mobile or web, which will be created next.
Here, I’ve added code (and commented it out) to use an external “searchApi” to search the CMS for specified content coming through the lambda’s event body. Let’s assume we are searching for my first and last name and spoofing the results in our response.
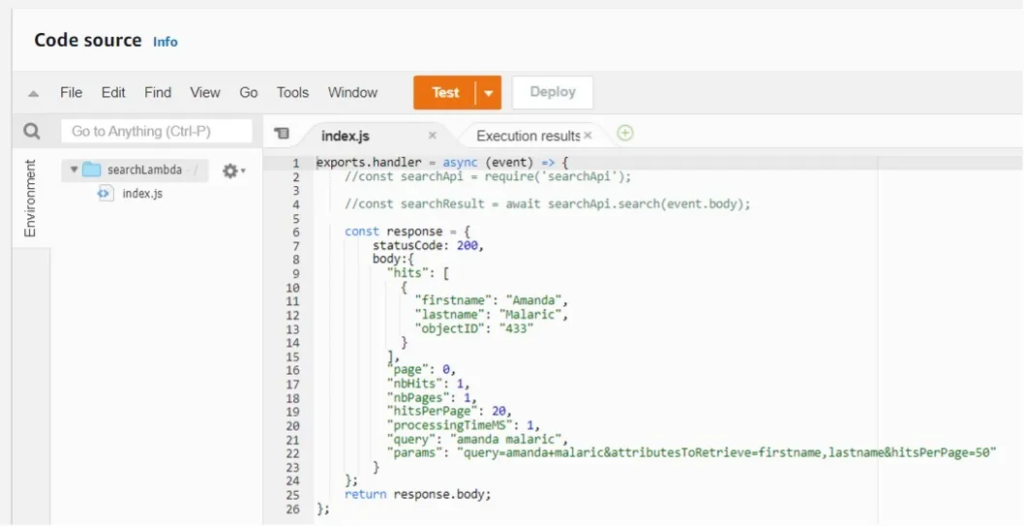
Create an Endpoint
There are many ways to build an endpoint, but for this project, we are using API Gateway.
Go into your configuration on your main AWS Lambda page and click “Add trigger.”
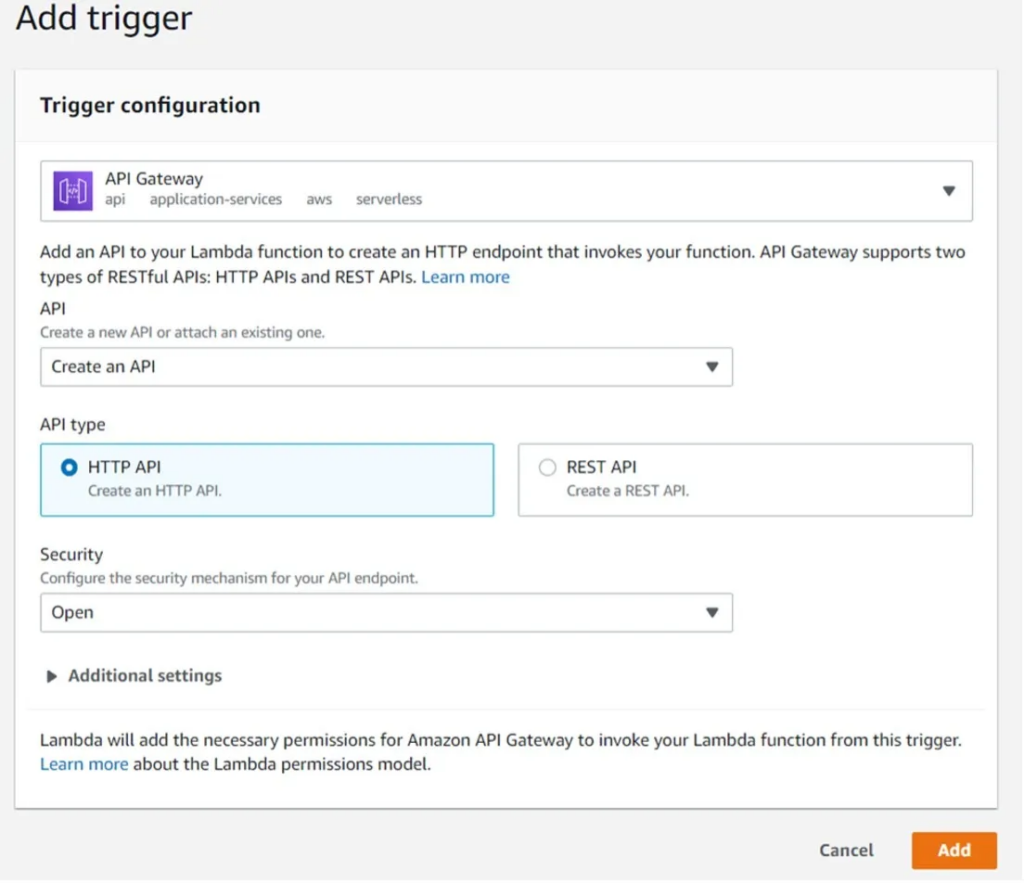
By clicking “Add,” we’ve created an API Gateway with our endpoint being type HTTP and having completely open security.
Important note: This is purely for demonstration purposes. Please secure your endpoints!
Now that we have our AWS Lambda and API Gateway in place, we can test!
Test with cURL
To test our work so far, we want to grab our API Gateway endpoint and start a curl command. There are a couple ways for you to find your API Gateway URL. An easy way is to go to your lambda and either click on your API Gateway trigger or by going to Configuration and then Triggers. The URL is the hyperlink after API endpoint.
Once you have your URL you can use a cURL command similar to this:
curl --location --request GET 'https://YOUR-API-ID.execute-api.REGION.amazonaws.com/default/searchLambda' \
--header 'Content-Type: application/json' \
--data-raw '{
"author":"amanda malaric"
}'The response will look like this:

Success!
If we take all the resources created and put them into one architecture diagram, it will look something like this:
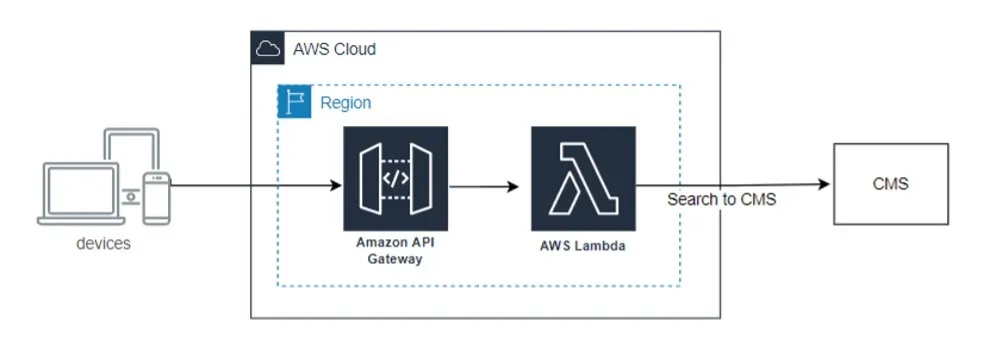
This project works! But should you stop there?
Here is a checklist to help you determine how robust your new feature is and whether it should be updated:
- Can I deploy the same setup in another account or environment?
- Can I commit and check in my code?
- Can I avoid committing keys, passwords, or other sensitive information?
- Can I create a pull request?
- Is this secure?
If you cannot do one or more of the items on this checklist, don’t worry. There is still plenty of time to make it right.
Make Your Code Right: Improving Your Lambda Function
As we review what we’ve created up to this point, we can identify some clear opportunities to make this code more robust and add value. Let’s explore some of the most important challenges to tackle — and their solutions.
Here is a proposed architecture diagram to make our services right:
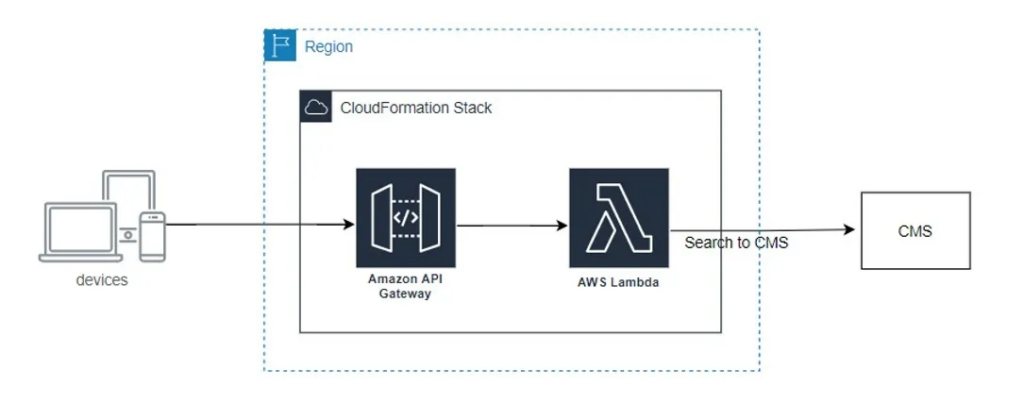
The overall structure may look unchanged, but we’ve removed a very bulky and unmaintainable aspect that will be touched.
Challenge: Limited Maintainability
Here’s a situation that every developer has faced: we get a new and shiny feature out there, only for changes to pop up. Normally we would go in and change the code, create our pull request, deploy, and then send it off for approval. Unfortunately, in its “make it work” state, no one knows what the lambda does, what it ties into or its configuration.
Solution: Infrastructure as Code
Welcome to the beautiful world of infrastructure as code! CloudFormation is going to be your best friend for this kind of thing. We leverage CloudFormation because it “uses templates, configuration files defined in JSON or YAML syntax, that are human-readable and can be easily edited, which you can use to define the resources you want to set up.”
As a result, this manual AWS Lambda and API Gateway configuration can be migrated down to your codebase for easy editing across team members. And as a bonus, CloudFormation creates consistency across environments. Each service becomes a CloudFormation resource: a code representation of your console service.
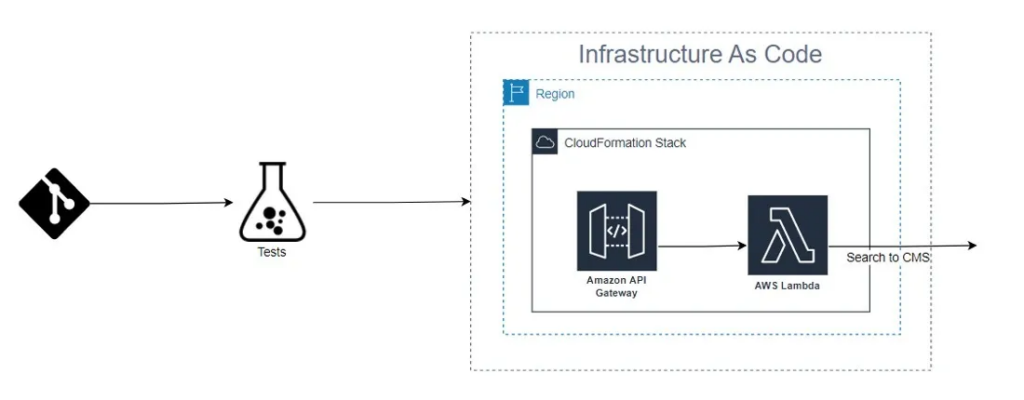
An example of an AWS Lambda in CloudFormation looks something like this:
searchFunction:
handler: index.js
role: !GetAtt searchFunctionExecutionRole.Arn
searchFunctionExecutionRole:
Type: AWS::IAM::Role
Properties:
RoleName: searchFunctionExecutionRole
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action: sts:AssumeRole
Policies:
- PolicyName: searchFunctionRolePolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- logs:CreateLogStream
- logs:CreateLogGroup
- logs:PutLogEventsNow that the configuration is saved in code, it can be deployed as needed to other environments.
Challenge: Creating More Than Needed
When we build our lambda manually, we can end up creating unwanted connections to resources. For example, we created an IAM Lambda execution role and policy, a log group, a log stream, and more! This inadvertently removed a level of granularity needed to add only the things you are going to use.
Solution: Restrict Your Function
While you could use a wildcard (*) to open all actions to a resource, infrastructure as code gives the programmer the ability to restrict given resources to given actions. As seen above:
Policies:
- PolicyName: searchFunctionRolePolicy
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- logs:CreateLogStream
- logs:CreateLogGroup
- logs:PutLogEvents
Resource: yourSearchFunctionArnIf we wanted to allow for a Dynamo action or any other action, we would now be able to define and maintain it here in the code. “Locking down” resources cuts down on cloud costs in the long run.
Challenge: Unexpected Errors
You may soon discover that your AWS Lambda is sending back errors out of the blue! You may not have changed anything in the console, so what gives?
Solution: Write Tests
You can give the code some much-needed insurance by writing tests. These tests can be done in the code base that you are slowly migrating things to (as defined above). I’ll quickly touch on unit tests and integration tests. Unit tests check the functionality of your services while integration tests check to see how all your services play together. You’ll want to make the tests as robust as possible so you aren’t caught off guard by bad parsing, invalid keys, or timeouts.
Make It Fast: Optimizing Your Lambda Function
In the fast-paced world of software development, we don’t typically have insights into how our solution may play with the other services years down the road. Anticipating scale and usage is an art that becomes difficult as we grow and attempt to optimize. But optimizations translate to long-term value added and cost savings — especially when you’re talking about scaling across thousands or hundreds of thousands of users or devices.
With our author search feature, we can make everything faster if we:
- Implement caching at the API Gateway.
- Configure the search engine to search against smaller chunks of data.
- Return only essential data.
As we continue to carry our tests and infrastructure as code with us to this point, let’s further improve upon the services. Here is how we would represent these updates in a high-level architecture diagram:
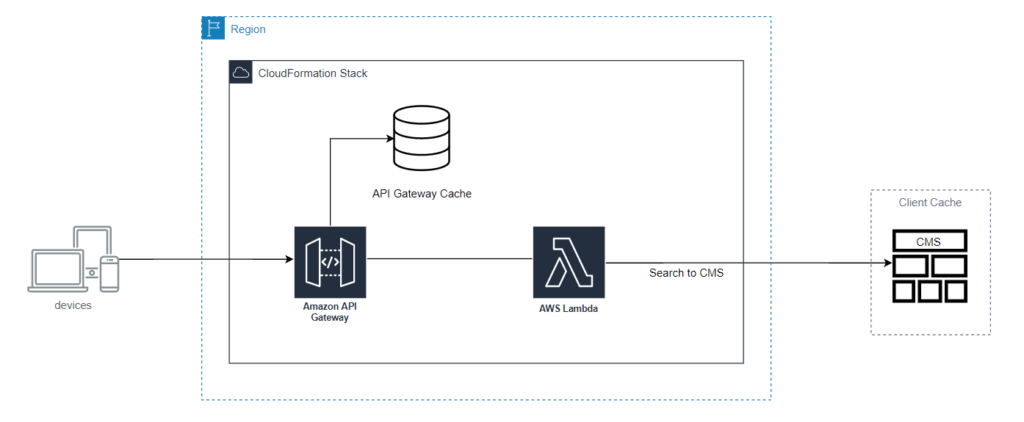
Next, let’s break each of these improvements down in depth.
Caching
Implementing caching for highly queried data such as site configuration or variables is a smart move. In doing so, you cut down on call time.
Caching is like having a local copy of the data or responses that you would pull from the search engine or API. By caching, queries are either searched against the cache or returned at the API Gateway level, rather than being sent all the way to and from the search engine. This means faster searches and less processing, which translates to a better user experience and cost savings. Caching on the search engine by using its client cache and/or configuring our API Gateway to allow caching gives us enhanced responsiveness.
Pulling in another service or updating an existing services configuration to help with caching may not be something you want to do for any number of reasons. If this is the case, you could use your lambda’s in-memory cache by storing reusable data outside of the handler instance. This persists beyond a single invoke if the lambda instance stays “hot.” Environment variables are a great candidate for this type of caching.
CMS Configuration
When performing a query on a large data set, we expect longer execution times to find the result requested. However, if we compartmentalize the data into, say, content types (products, authors, etc.), we can query smarter and faster. For example, if we sent “John” to the search engine, we would get results for any page in the CMS that has “John” in it. That could be product pages, author names, categories, articles, and anything else that exists in the CMS.
But if we just want to find a particular author whose name included “John,” we can send in that content type and query through our endpoint because our search engine is configured to query compartmentally. That list of results will take less time to complete and be more specific, which will make life easier for users and save costs.
Return the Appropriate Data
A given endpoint’s resulting payload should satisfy the requirements needed for the end consumer but not overwhelm them with too many data attributes. For instance, if our endpoint only needs to return an object with one attribute in it, we would not want to return more than that. With our “John” author example, we wouldn’t need to return every attribute associated with that author. Maybe mobile only requires the unique Id or the associated books written by the author.
Once again, by cutting back on returning unnecessary attributes, we save time and save on processing.
Struggling With Messy Code? Building Something New? Talk to Vervint!
Vervint’s team of experienced developers, architects, delivery leads and strategists can help you identify opportunities, create quality code, and build long-term efficiencies that will drive value at scale. Want to get a conversation started? Let’s talk! We look forward to hearing from you.

